SERVERの最近のブログ記事
自分用メモ
CentOS6 ミニマルでインストール
そのままVMwareでフルクローンし、実験しようと思った時
なぜか、ネットワークが反応しない
ifconfig
lo
しか・・・・・・
とりあえず、こういうこ時は再起動
/etc/rc.d/init.d/network restart
Device eth0 does not seem to be present, delaying initialization.
ん????
とりあえず、ここを参考に対応してみる
俺の覚え書き
【CentOS6】NICが有効化できないときの対処
ifconfig -a
確かにeth1に振られている・・・・・
vi /etc/sysconfig/network-scripts/ifcfg-eth0
で、MACアドレス書き換え
vi /etc/udev/rules.d/70-persistent-net.rules
で、該当ルールの削除
vi /etc/rc.d/init.d/network restart
しかし、同じエラー。。。。。。
ここから、小一時間悩む
えーい、インスタンスの再起動。。。。
つまり
reboot
そしたら、問題なく立ち上がっていた
サーバーって難しいね。。。。。。
弊社でテスト環境で出している放置サーバーでトラブルがあり、その辺の対応でのメモ
OSはCentOS4、、しかも相当古い。4.4ぐらい。
yum update 出来ない。
たしか、レポ終わっているんだよなぁと、うすら覚えしているので、早速ググる!
レポをいじる方向で
vi /etc/yum.repos.d/CentOS-Base.repo
で編集
各mirrorの行をコメントアウト
baseurlを付け足す
↓こんな感じ
[base]
name=CentOS-$releasever - Base
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
baseurl=http://vault.centos.org/4.9/os/$basearch/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-centos4
[update]
name=CentOS-$releasever - Updates
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
baseurl=http://vault.centos.org/4.9/updates/$basearch/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-centos4
[addons]
name=CentOS-$releasever - Addons
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=addons
#baseurl=http://mirror.centos.org/centos/$releasever/addons/$basearch/
baseurl=http://vault.centos.org/4.9/addons/$basearch/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-centos4
[extras]
name=CentOS-$releasever - Extras
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras
#baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
baseurl=http://vault.centos.org/4.9/extras/$basearch/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-centos4
[centosplus]
name=CentOS-$releasever - Plus
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus
#baseurl=http://mirror.centos.org/centos/$releasever/centosplus/$basearch/
baseurl=http://vault.centos.org/4.9/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-centos4
[contrib]
name=CentOS-$releasever - Contrib
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=contrib
#baseurl=http://mirror.centos.org/centos/$releasever/contrib/$basearch/
baseurl=http://vault.centos.org/4.9/contrib/$basearch/
gpgcheck=1
enabled=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-centos4
↑
ここまで
書き換えたら、yum update出来ました。
実は、サーバーをローカルから、グローバルに変更する作業も頼まれていたので、その辺シコシコ作業をやっていたのですが、大はまり。
答えは簡単なところだったのですが、、、ちょっと頭が沸いて居るなぁと
参考は下のサイトです、御世話になりました<(_ _)>
Dマイナー思考
yum updateできなくなった古いCentOSでyumコマンドを復活させる方法
追記
それと、このサーバーでずっと問題になっていた、朝4時くらいでリブートする問題
何となく iptables と kernelの問題だと判っていたのですが、稼働サーバーで適用するのが怖すぎました。
Kernel panic when unloading ip conntrack modules
↑
この問題
このサーバーは、再起動OKのサーバーなので
vi /etc/sysctl.conf
kernel.panic = xx
を書いて誤魔化していました(xxは秒数)
xxで指定した時間で再起動します。
綺麗なぐらい、ほぼ毎日再起動されていました。
ただ、今回これを直さないと、IP変更出来ないんじゃないかと気づき(FWのセキュリティの問題)、思い切って変更しました
アップデートファイルは243個、新規インストールも3ファイル、、、
このサーバーは、非常に古いサーバーなので、アップデートが終わるまで、30分以上掛かりました。
立ち上がってこなかったら・・・・・は考えずに
reboot
上がってきてくれました。
そして、セキュリティ関連もばっちり利いてくれて、万事解決です。
ここ最近、電源系のトラブルで、お客様にご迷惑をおかけしてしまいました。
トラブルは、トラブルで、言い訳などないのですが、2つとも、トラブルの切り分けが、なんとも言いにくい部分なので、つらいところでした。
1つ目は、UPS関連、使っているUPSはUPS自身にブレカーが付いているタイプで、こちらのブレーカーが効かず、そのコンセント上の、ブレーカーが、落ちていたというものでした。
ただの電力計算ミスなら、こちらのミスなのですが、なぜか、UPS側のブレーカーが、効かず、とりあえず、コンセントを変更する、つないでいる、サーバーの台数を減らすということで、対応しました。
2つ目は、これは、タイミングが悪かったのですが、メインの人間が、いない時に、UPSがストップしていた、というインシデント。バッテリーも切り替わらず、落ちてました。
当時、ゲリラ豪雨で、雷が理由の可能性もあるのですが、これも、はっきりと理由が判らず。
駆けつけ後、コンセントを切り替え、起動させると、UPSは、満充電のまま、起動
ただ、電源の引きまわしとして、一番短い経路のコンセントなので、雷の影響は、絶対ないとも言えず、どうなんだろうと、思っています。
ただ、一番当社で古いUPSではあるので、即新しい物注文し、次のメンテナンスで交換予定です。
こういう気持ち悪い、はっきりしないトラブルが続いたので、ホントに、頭が回転しっぱなしです。
ご迷惑を、おかけした皆様には、すいませんが、トラブル周りは、できるだけ、迅速に対応して、次回無きように、しますので、宜しくお願いします。
実際、7月末までに、新管理体系、さらに、運用マネージメントを導入する予定だったので、その前に、このトラブルの連続は、悔しいところでした。
毎年、7月には、何か起こります。去年も、HW故障で、ややこしいトラブルがありました。通常の故障率の範疇に、完全に入る故障で、普通なら、全く問題ないものだったのですが、、、、、、^^;
一般的には、こちらは、一切問題がないものだったのですが、勉強になりました。
とりあえず、よりサービスの向上にはかります
昨年10月から落ち着いていた、トラブルが、、、、
若干種類は違うのだが、山は明日早朝、
とりあえず、予定が更に2週間は見えません^^;
お仕事ネタ、久しぶりにハウジング作業
こことは、初めてのお付き合いです
モニターはいらないと何度も行っていたのですが、モニターまで送ってる(^^ゞ
事前にネットワークの環境は送っているのに、ルーターの設定が、、、
言おうか、言わまいかw
サーバーのメンテナンスで、転送されていた、メールをDL
3万通越えると、DLも20分超えるのね^^;
自分用のメモ
json をcentos php5.1.6の環境で使う
yum install php-devel
pecl install json
extension=json.so
その場その場で付け足していく、開発環境は厳しいですw
管理しているサーバーで、一番負荷が高いと思われる奴が
[root@kaiman ~]# uptime
23:16:35 up 279 days, 21:40, 1 user, load average: 197.36, 186.32, 136.27
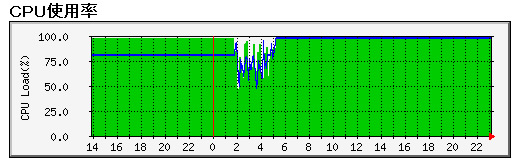
1時くらいまで常にこんな感じなんだよな、、、、、
メモリ3G、XEON3.4Gデュアルなので、とりあえずは動いているけど、大丈夫か???
とりあえず、まだ、IOも、メモリもいけそうなので、落ちるまで様子見
ちなみに、このサーバー1つのWEBサイトが動いているだけ・・・・
しかし、ピーク300近くなるんですよねLA
MTTR
平均復旧時間
MTBF
平均故障間隔
TPS
単位時間当たりのトランザクション数
■性能設計のすすめ方
業務及び性能目標の明確化
性能モデルの選定
システムサイジング
流量制御設計
■流量制御設計の対象箇所
ウェブサーバーの同時実行窓口数
APサーバーの同時実行スレッド数、及び、実行待ちリクエスト数
プログラムが使用するインスタンスプール及び、DBコネクションプール
同時アクセス数=同時実行窓口数≧(実行待ちリクエスト数 + 同時時効スレッド数)
同時実行窓口数=HTML等の静的コンテンツへのアクセス数+(実行待ちリクエスト数+同時実行スレッド数)
インスタンスプール≧同時実行スレッド数
DBコネクションプール≧同時実行スレッド数
webシステムの同時実行スレッド数=TPS×APサーバー内部保留時間
同時実行スレッド数=(TPS×APサーバー内部保留時間(秒))/ マシン台数
■タイムアウトに対しての設定対象
リダイレクタ・タイムアウト(ウェブサーバーがリクエストをAPサーバーに送信してから返信を受け取るまでの時間)
業務アプリケーションタイムアウト(業務プログラムのメソッドを実行開始してから終了するまでの時間)
トランザクションタイムアウト(業務プログラムにおいてDBアクセスなどのトランザクション開始から終了する迄の時間)
COBIT
control objectives for information and relater technology
サービスの提供
セキュリティの管理と継続性の管理
ユーザー向けサービス・サポート、データと運用設備の管理
ITIL
it infrastructure library
SLA
service level agreement
SLAの例
サービス提供時間
障害復旧時間(MTTR)
サービス稼働率
ネットワーク稼働率
ネットワーク利用率
セキュリティ対策
レスポンスタイム
スループット
■運用設計の目的と進め方
サービスレベル管理
キャパシティ管理
継続的なサービスの保証
セキュリティ
インシデント管理
問題管理
構成管理
データ管理
オペレーション管理
そのほか
■障害運用のポイント
障害の発生を予防する 障害予防運用設計
障害が発生してしまった場合に障害を分析する 障害発生時運用
障害発生後のシステム復旧 障害回復
■運用サーバーの管理モジュールの配備場所
■運用管理ツールの導入検討
・ウェブアプリケーション・サーバーの運用管理機能
・総合監視
・リソース監視
・プロセス監視
・ネットワーク監視
・ジョブスケジューラ
・障害解析・性能測定ツール
・デプロイメント管理
・通報管理
・キャパシティ管理
・問題管理
■チューニング
性能測定の実施
1,通常想定される負荷
2,通常想定される負荷の2倍から3倍の負荷
3,スループット限界ポイント前後の負荷
4,スループット限界ポイント直前の負荷を長時間掛ける
・業務アプリケーションのロジックチューニング
・各種アプリケーションサーバーや、DBサーバーなどのプラットフォームのパラメーターチューニング
・ハードウェアの増強
平均復旧時間
MTBF
平均故障間隔
TPS
単位時間当たりのトランザクション数
■性能設計のすすめ方
業務及び性能目標の明確化
性能モデルの選定
システムサイジング
流量制御設計
■流量制御設計の対象箇所
ウェブサーバーの同時実行窓口数
APサーバーの同時実行スレッド数、及び、実行待ちリクエスト数
プログラムが使用するインスタンスプール及び、DBコネクションプール
同時アクセス数=同時実行窓口数≧(実行待ちリクエスト数 + 同時時効スレッド数)
同時実行窓口数=HTML等の静的コンテンツへのアクセス数+(実行待ちリクエスト数+同時実行スレッド数)
インスタンスプール≧同時実行スレッド数
DBコネクションプール≧同時実行スレッド数
webシステムの同時実行スレッド数=TPS×APサーバー内部保留時間
同時実行スレッド数=(TPS×APサーバー内部保留時間(秒))/ マシン台数
■タイムアウトに対しての設定対象
リダイレクタ・タイムアウト(ウェブサーバーがリクエストをAPサーバーに送信してから返信を受け取るまでの時間)
業務アプリケーションタイムアウト(業務プログラムのメソッドを実行開始してから終了するまでの時間)
トランザクションタイムアウト(業務プログラムにおいてDBアクセスなどのトランザクション開始から終了する迄の時間)
COBIT
control objectives for information and relater technology
サービスの提供
セキュリティの管理と継続性の管理
ユーザー向けサービス・サポート、データと運用設備の管理
ITIL
it infrastructure library
SLA
service level agreement
SLAの例
サービス提供時間
障害復旧時間(MTTR)
サービス稼働率
ネットワーク稼働率
ネットワーク利用率
セキュリティ対策
レスポンスタイム
スループット
■運用設計の目的と進め方
サービスレベル管理
キャパシティ管理
継続的なサービスの保証
セキュリティ
インシデント管理
問題管理
構成管理
データ管理
オペレーション管理
そのほか
■障害運用のポイント
障害の発生を予防する 障害予防運用設計
障害が発生してしまった場合に障害を分析する 障害発生時運用
障害発生後のシステム復旧 障害回復
■運用サーバーの管理モジュールの配備場所
■運用管理ツールの導入検討
・ウェブアプリケーション・サーバーの運用管理機能
・総合監視
・リソース監視
・プロセス監視
・ネットワーク監視
・ジョブスケジューラ
・障害解析・性能測定ツール
・デプロイメント管理
・通報管理
・キャパシティ管理
・問題管理
■チューニング
性能測定の実施
1,通常想定される負荷
2,通常想定される負荷の2倍から3倍の負荷
3,スループット限界ポイント前後の負荷
4,スループット限界ポイント直前の負荷を長時間掛ける
・業務アプリケーションのロジックチューニング
・各種アプリケーションサーバーや、DBサーバーなどのプラットフォームのパラメーターチューニング
・ハードウェアの増強
